Slush 2015 brought together 15000 attendees and more than 1700 startups for the two-day event on 11th and 12th of November. 800 investors arrived in Helsinki to meet startups in nearly 4000 pre-booked meetings. Like last year, UpCloud was one of the key partners of Slush and we provided the IT infrastructure for the event. In this post, we’ll look at how Slush built their cloud infrastructure on top of UpCloud’s cloud hosting service.

While the IT of a 2-day event might not seem complex, there is actually quite a lot of going on behind the scenes. The different applications hosted on UpCloud at Slush include the registration, the ticket shop, the matchmaking web app for investors and startups which uses data from the registration, mobile apps (iOS/Android), slush.org website (WordPress) and the jobs web app listing over a thousand job openings for companies involved with Slush. The web apps were mostly built with Angular.js and the APIs were built with Node.js and Python Django.
The cloud infrastructure described in this post is mostly built by Emblica, a company that partly forms the IT team at Slush. Some other components of the infrastructure were created with partners too, such as the website running WordPress was built by Evermade and the mobile apps were built by Qvik.
Last year Slush’s infrastructure had a somewhat traditional setup with a load balancer and web servers. This year, however, the software started to move towards a microarchitecture and a convenient way to do blue-green deployments with the applications was wished by the developers. They set up a MariaDB server (Galera enabled so it can scale up if needed) and also a custom object storage for persistent data and state. For handling the load balancing and Django + NodeJS apps, they wanted to try out a cluster; each node would run a load balancer and all of the apps distribute the load evenly across the cluster.
Experimenting with Docker containers and a CoreOS cluster
CoreOS is essentially an operating system built for running containers in a cluster and Docker is the container technology everyone is talking about. So with the help of etcd and Fleetd, a scalable CoreOS cluster was created where every node runs HAProxy that balances traffic to the containerized applications running in the cluster. This way, any number of the cluster’s nodes can accept requests from the internet and still balance the load quite evenly – it also allows scaling the size of the cluster without touching DNS at all, just like a traditional load balancer + web servers setup would work.
The following picture illustrates Slush’s setup:
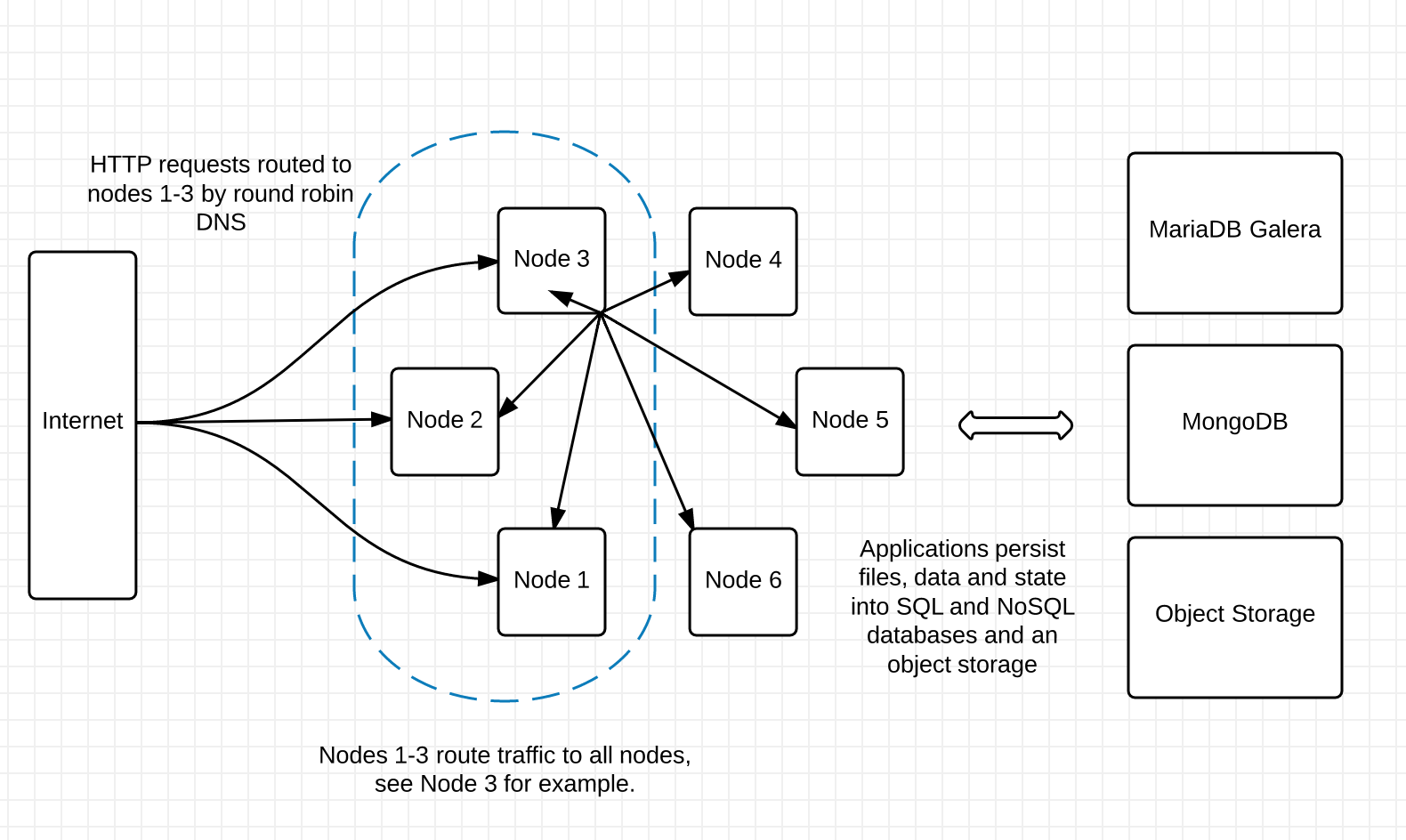
The arrows from Node 3 illustrate the HAProxy load balancing; similar balancing is being done by all nodes in round-robin DNS (Nodes 1-3 in this picture).
In addition to the CoreOS cluster, Emblica built a simple dashboard that manages the cluster’s deployments; some of the features include one-click deploys from Github, easy shell access for running maintenance tasks like migrations and easy management of hostnames thanks to HAProxy. This allowed for a quick staging-production (or blue-green) flow with continuous integration and continuous deployment.
Inside the cluster
All software hosted by the cluster runs in Docker containers and on several nodes for redundancy and performance. Failure of a node is noticed by the cluster and immediately removed from load balancing. This kind of redundancy is provided by CoreOS’s distributed etcd database that tracks the locations of containers in the cluster and Fleetd that manages services in the cluster. Whenever the amount of nodes changes, the containers are distributed evenly by Fleetd so that services keep running flawlessly when scaling up or down, or if nodes crash.
Running a containerized application is done as a Fleetd service. When they deploy new software, the workflow begins from Github where all new code is stored and from where CircleCI runs tests on every new commit. After tests have passed at CircleCI, a custom system pulls code from Github and builds a new Docker image. If this image is to be deployed, a new Fleetd service is created that is then distributed to the cluster. When this new service passes health checks, it is added to the HAProxies running on every node. If the new software was a newer version of already running software, the old one can be removed from the HAProxy load balancing.
Quite a tech stack – overkill?
Short answer: yes. The infrastructure could have been built in a simpler way even though Slush does receive quite extensive traffic peaks before and during the event. However, this project was also a practice for Slush, its IT-team and Emblica to build scalable software and infrastructure on top of UpCloud. In addition, it was also a way to demonstrate how to build scalable cloud infrastructure on top of “plain IaaS” rather than using PaaS components which promise scalability but usually come with a quite high cost and loss of control.
Try UpCloud for free!
In case you would like to learn more about some specific detail of the infrastructure described here, don’t hesitate to contact UpCloud at our sales ([email protected]).
We offer a Free Trial to help you to speed up your WordPress or eCommerce! Fastest cloud servers with 2x the performance as the competition & 100% uptime SLA. Deploy in seconds, pay less. Get started now! Free trials available here
Cover photo by Kai Kuusisto